Description
Why Would You Use Description on Dataset?
Adding a description and related link to a dataset can provide important information about the data, such as its source, collection methods, and potential uses. This can help others understand the context of the data and how it may be relevant to their own work or research. Including a related link can also provide access to additional resources or related datasets, further enriching the information available to users.
Goal Of This Guide
This guide will show you how to
- Read dataset description: read a description of a dataset.
- Read column description: read a description of columns of a dataset`.
- Add dataset description: add a description and a link to dataset.
- Add column description: add a description to a column of a dataset.
Prerequisites
For this tutorial, you need to deploy DataHub Quickstart and ingest sample data. For detailed steps, please refer to Datahub Quickstart Guide.
Before adding a description, you need to ensure the targeted dataset is already present in your datahub. If you attempt to manipulate entities that do not exist, your operation will fail. In this guide, we will be using data from sample ingestion.
In this example, we will add a description to user_name column of a dataset fct_users_deleted.
Read Description on Dataset
- GraphQL
- Curl
- Python
query {
dataset(urn: "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)") {
properties {
description
}
}
}
If you see the following response, the operation was successful:
{
"data": {
"dataset": {
"properties": {
"description": "table containing all the users deleted on a single day"
}
}
},
"extensions": {}
}
curl --location --request POST 'http://localhost:8080/api/graphql' \
--header 'Authorization: Bearer <my-access-token>' \
--header 'Content-Type: application/json' \
--data-raw '{ "query": "query { dataset(urn: \"urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)\") { properties { description } } }", "variables":{}}'
Expected Response:
{
"data": {
"dataset": {
"properties": {
"description": "table containing all the users deleted on a single day"
}
}
},
"extensions": {}
}
# Inlined from /metadata-ingestion/examples/library/dataset_query_description.py
from datahub.emitter.mce_builder import make_dataset_urn
# read-modify-write requires access to the DataHubGraph (RestEmitter is not enough)
from datahub.ingestion.graph.client import DatahubClientConfig, DataHubGraph
# Imports for metadata model classes
from datahub.metadata.schema_classes import DatasetPropertiesClass
dataset_urn = make_dataset_urn(platform="hive", name="fct_users_created", env="PROD")
gms_endpoint = "http://localhost:8080"
graph = DataHubGraph(DatahubClientConfig(server=gms_endpoint))
# Query multiple aspects from entity
result = graph.get_aspects_for_entity(
entity_urn=dataset_urn,
aspects=["datasetProperties"],
aspect_types=[DatasetPropertiesClass],
)["datasetProperties"]
if result:
print(result.description)
Read Description on Columns
- GraphQL
- Curl
- Python
query {
dataset(urn: "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)") {
schemaMetadata {
fields {
fieldPath
description
}
}
}
}
If you see the following response, the operation was successful:
{
"data": {
"dataset": {
"schemaMetadata": {
"fields": [
{
"fieldPath": "user_name",
"description": "Name of the user who was deleted"
},
...
{
"fieldPath": "deletion_reason",
"description": "Why the user chose to deactivate"
}
]
}
}
},
"extensions": {}
}
curl --location --request POST 'http://localhost:8080/api/graphql' \
--header 'Authorization: Bearer <my-access-token>' \
--header 'Content-Type: application/json' \
--data-raw '{ "query": "query { dataset(urn: \"urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)\") { schemaMetadata { fields { fieldPath description } } } }", "variables":{}}'
Expected Response:
{
"data": {
"dataset": {
"schemaMetadata": {
"fields": [
{
"fieldPath": "user_name",
"description": "Name of the user who was deleted"
},
{
"fieldPath": "timestamp",
"description": "Timestamp user was deleted at"
},
{ "fieldPath": "user_id", "description": "Id of the user deleted" },
{
"fieldPath": "browser_id",
"description": "Cookie attached to identify the browser"
},
{
"fieldPath": "session_id",
"description": "Cookie attached to identify the session"
},
{
"fieldPath": "deletion_reason",
"description": "Why the user chose to deactivate"
}
]
}
}
},
"extensions": {}
}
# Inlined from /metadata-ingestion/examples/library/dataset_query_description_on_columns.py
from datahub.emitter.mce_builder import make_dataset_urn
# read-modify-write requires access to the DataHubGraph (RestEmitter is not enough)
from datahub.ingestion.graph.client import DatahubClientConfig, DataHubGraph
# Imports for metadata model classes
from datahub.metadata.schema_classes import SchemaMetadataClass
dataset_urn = make_dataset_urn(platform="hive", name="fct_users_created", env="PROD")
gms_endpoint = "http://localhost:8080"
graph = DataHubGraph(DatahubClientConfig(server=gms_endpoint))
# Query multiple aspects from entity
result = graph.get_aspects_for_entity(
entity_urn=dataset_urn,
aspects=["schemaMetadata"],
aspect_types=[SchemaMetadataClass],
)["schemaMetadata"]
if result:
column_descriptions = [
{field.fieldPath: field.description} for field in result.fields
]
print(column_descriptions)
Add Description on Dataset
- GraphQL
- Curl
- Python
mutation updateDataset {
updateDataset(
urn:"urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)",
input: {
editableProperties: {
description: "## The Real Estate Sales Dataset\nThis is a really important Dataset that contains all the relevant information about sales that have happened organized by address.\n"
}
institutionalMemory: {
elements: {
author: "urn:li:corpuser:jdoe"
url: "https://wikipedia.com/real_estate"
description: "This is the definition of what real estate means"
}
}
}
) {
urn
}
}
Expected Response:
{
"data": {
"updateDataset": {
"urn": "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)"
}
},
"extensions": {}
}
curl --location --request POST 'http://localhost:8080/api/graphql' \
--header 'Authorization: Bearer <my-access-token>' \
--header 'Content-Type: application/json' \
--data-raw '{
"query": "mutation updateDataset { updateDataset( urn:\"urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)\", input: { editableProperties: { description: \"## The Real Estate Sales Dataset\nThis is a really important Dataset that contains all the relevant information about sales that have happened organized by address.\n\" } institutionalMemory: { elements: { author: \"urn:li:corpuser:jdoe\", url: \"https://wikipedia.com/real_estate\", description: \"This is the definition of what real estate means\" } } } ) { urn } }",
"variables": {}
}'
Expected Response:
{
"data": {
"updateDataset": {
"urn": "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)"
}
},
"extensions": {}
}
# Inlined from /metadata-ingestion/examples/library/dataset_add_documentation.py
import logging
import time
from datahub.emitter.mce_builder import make_dataset_urn
from datahub.emitter.mcp import MetadataChangeProposalWrapper
# read-modify-write requires access to the DataHubGraph (RestEmitter is not enough)
from datahub.ingestion.graph.client import DatahubClientConfig, DataHubGraph
# Imports for metadata model classes
from datahub.metadata.schema_classes import (
AuditStampClass,
EditableDatasetPropertiesClass,
InstitutionalMemoryClass,
InstitutionalMemoryMetadataClass,
)
log = logging.getLogger(__name__)
logging.basicConfig(level=logging.INFO)
# Inputs -> owner, ownership_type, dataset
documentation_to_add = "## The Real Estate Sales Dataset\nThis is a really important Dataset that contains all the relevant information about sales that have happened organized by address.\n"
link_to_add = "https://wikipedia.com/real_estate"
link_description = "This is the definition of what real estate means"
dataset_urn = make_dataset_urn(platform="hive", name="realestate_db.sales", env="PROD")
# Some helpful variables to fill out objects later
now = int(time.time() * 1000) # milliseconds since epoch
current_timestamp = AuditStampClass(time=now, actor="urn:li:corpuser:ingestion")
institutional_memory_element = InstitutionalMemoryMetadataClass(
url=link_to_add,
description=link_description,
createStamp=current_timestamp,
)
# First we get the current owners
gms_endpoint = "http://localhost:8080"
graph = DataHubGraph(config=DatahubClientConfig(server=gms_endpoint))
current_editable_properties = graph.get_aspect(
entity_urn=dataset_urn, aspect_type=EditableDatasetPropertiesClass
)
need_write = False
if current_editable_properties:
if documentation_to_add != current_editable_properties.description:
current_editable_properties.description = documentation_to_add
need_write = True
else:
# create a brand new editable dataset properties aspect
current_editable_properties = EditableDatasetPropertiesClass(
created=current_timestamp, description=documentation_to_add
)
need_write = True
if need_write:
event: MetadataChangeProposalWrapper = MetadataChangeProposalWrapper(
entityUrn=dataset_urn,
aspect=current_editable_properties,
)
graph.emit(event)
log.info(f"Documentation added to dataset {dataset_urn}")
else:
log.info("Documentation already exists and is identical, omitting write")
current_institutional_memory = graph.get_aspect(
entity_urn=dataset_urn, aspect_type=InstitutionalMemoryClass
)
need_write = False
if current_institutional_memory:
if link_to_add not in [x.url for x in current_institutional_memory.elements]:
current_institutional_memory.elements.append(institutional_memory_element)
need_write = True
else:
# create a brand new institutional memory aspect
current_institutional_memory = InstitutionalMemoryClass(
elements=[institutional_memory_element]
)
need_write = True
if need_write:
event = MetadataChangeProposalWrapper(
entityUrn=dataset_urn,
aspect=current_institutional_memory,
)
graph.emit(event)
log.info(f"Link {link_to_add} added to dataset {dataset_urn}")
else:
log.info(f"Link {link_to_add} already exists and is identical, omitting write")
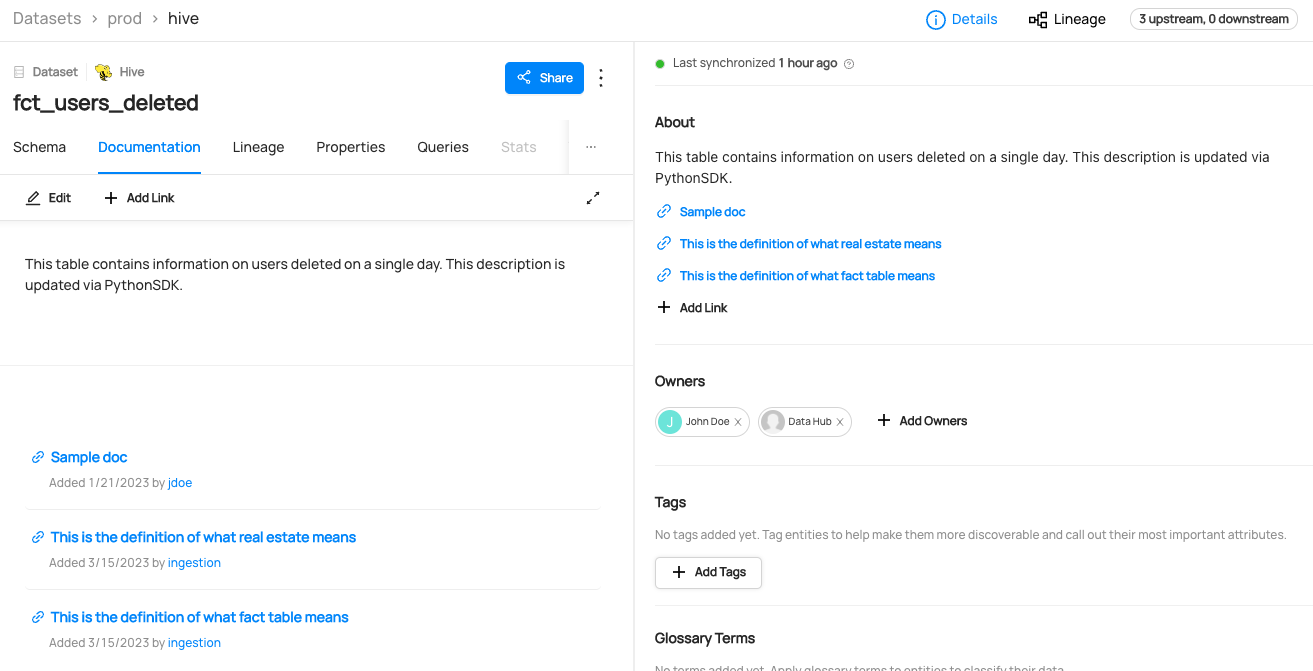
Expected Outcomes of Adding Description on Dataset
You can now see the description is added to fct_users_deleted.
Add Description on Column
- GraphQL
- Curl
- Python
mutation updateDescription {
updateDescription(
input: {
description: "Name of the user who was deleted. This description is updated via GrpahQL.",
resourceUrn:"urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)",
subResource: "user_name",
subResourceType:DATASET_FIELD
}
)
}
Note that you can use general markdown in description. For example, you can do the following.
mutation updateDescription {
updateDescription(
input: {
description: """
### User Name
The `user_name` column is a primary key column that contains the name of the user who was deleted.
""",
resourceUrn:"urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)",
subResource: "user_name",
subResourceType:DATASET_FIELD
}
)
}
updateDescription currently only supports Dataset Schema Fields, Containers.
For more information about the updateDescription mutation, please refer to updateLineage.
If you see the following response, the operation was successful:
{
"data": {
"updateDescription": true
},
"extensions": {}
}
curl --location --request POST 'http://localhost:8080/api/graphql' \
--header 'Authorization: Bearer <my-access-token>' \
--header 'Content-Type: application/json' \
--data-raw '{ "query": "mutation updateDescription { updateDescription ( input: { description: \"Name of the user who was deleted. This description is updated via GrpahQL.\", resourceUrn: \"urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)\", subResource: \"user_name\", subResourceType:DATASET_FIELD }) }", "variables":{}}'
Expected Response:
{ "data": { "updateDescription": true }, "extensions": {} }
# Inlined from /metadata-ingestion/examples/library/dataset_add_column_documentation.py
import logging
import time
from datahub.emitter.mce_builder import make_dataset_urn
from datahub.emitter.mcp import MetadataChangeProposalWrapper
# read-modify-write requires access to the DataHubGraph (RestEmitter is not enough)
from datahub.ingestion.graph.client import DatahubClientConfig, DataHubGraph
# Imports for metadata model classes
from datahub.metadata.schema_classes import (
AuditStampClass,
EditableSchemaFieldInfoClass,
EditableSchemaMetadataClass,
InstitutionalMemoryClass,
)
from datahub.utilities.urns.field_paths import get_simple_field_path_from_v2_field_path
log = logging.getLogger(__name__)
logging.basicConfig(level=logging.INFO)
# Inputs -> owner, ownership_type, dataset
documentation_to_add = (
"Name of the user who was deleted. This description is updated via PythonSDK."
)
dataset_urn = make_dataset_urn(platform="hive", name="fct_users_deleted", env="PROD")
column = "user_name"
field_info_to_set = EditableSchemaFieldInfoClass(
fieldPath=column, description=documentation_to_add
)
# Some helpful variables to fill out objects later
now = int(time.time() * 1000) # milliseconds since epoch
current_timestamp = AuditStampClass(time=now, actor="urn:li:corpuser:ingestion")
# First we get the current owners
gms_endpoint = "http://localhost:8080"
graph = DataHubGraph(config=DatahubClientConfig(server=gms_endpoint))
current_editable_schema_metadata = graph.get_aspect(
entity_urn=dataset_urn,
aspect_type=EditableSchemaMetadataClass,
)
need_write = False
if current_editable_schema_metadata:
for fieldInfo in current_editable_schema_metadata.editableSchemaFieldInfo:
if get_simple_field_path_from_v2_field_path(fieldInfo.fieldPath) == column:
# we have some editable schema metadata for this field
field_match = True
if documentation_to_add != fieldInfo.description:
fieldInfo.description = documentation_to_add
need_write = True
else:
# create a brand new editable dataset properties aspect
current_editable_schema_metadata = EditableSchemaMetadataClass(
editableSchemaFieldInfo=[field_info_to_set],
created=current_timestamp,
)
need_write = True
if need_write:
event: MetadataChangeProposalWrapper = MetadataChangeProposalWrapper(
entityUrn=dataset_urn,
aspect=current_editable_schema_metadata,
)
graph.emit(event)
log.info(f"Documentation added to dataset {dataset_urn}")
else:
log.info("Documentation already exists and is identical, omitting write")
current_institutional_memory = graph.get_aspect(
entity_urn=dataset_urn, aspect_type=InstitutionalMemoryClass
)
need_write = False
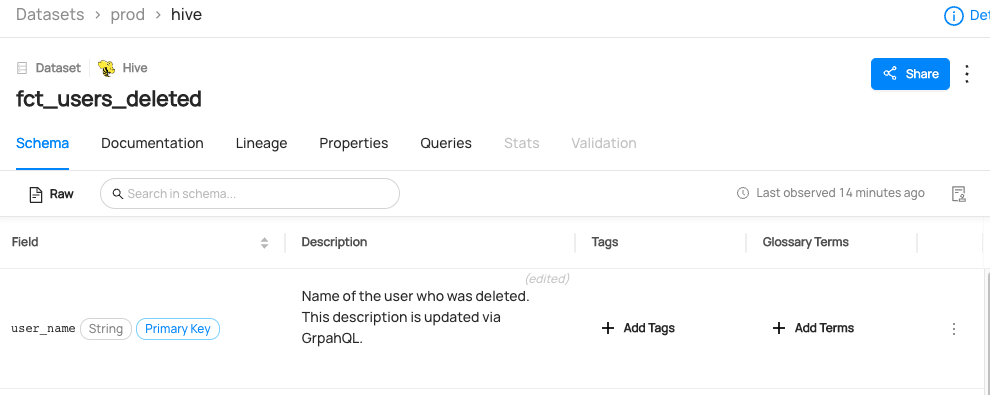
Expected Outcomes of Adding Description on Column
You can now see column description is added to user_name column of fct_users_deleted.